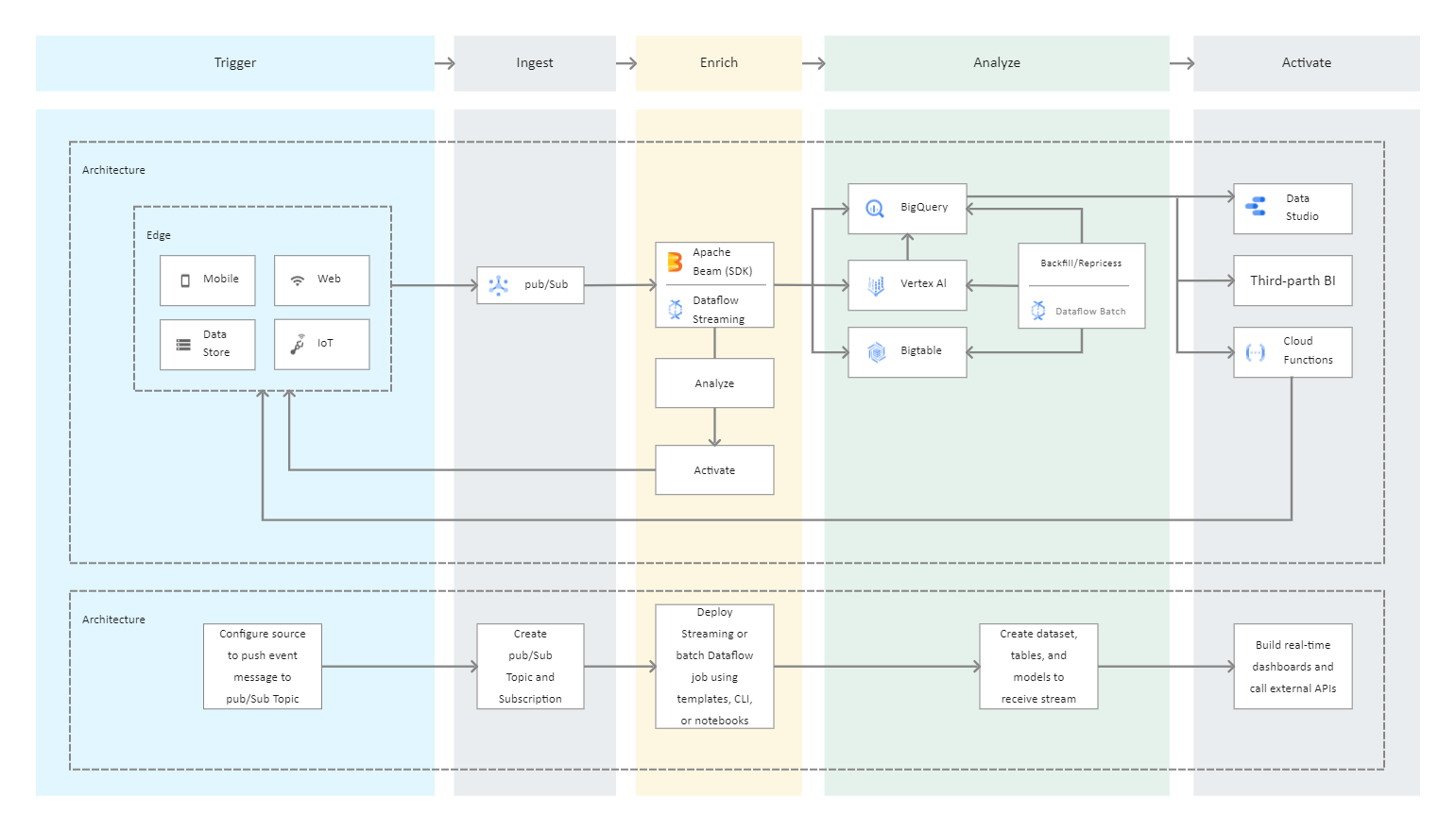
GCP Dataflow is used for batch or stream data processing and enrichment for use cases such as analysis, machine learning, and data warehousing. GCP Dataflow is a serverless, fast, and low-cost service that can handle both stream and batch processing. It adds portability to processing jobs written with the open-source Apache Beam libraries and reduces operational overhead for your data engineering teams by automating infrastructure provisioning and cluster management. The data from the source is read into a PCollection. Because a PCollection is intended to be distributed across multiple machines, the 'P' stands for "parallel." Then it performs one or more transform operations on the PCollection. A new PCollection is created each time it runs a transform. Because Pcollections are immutable, this is the case.


 Desktop
Desktop