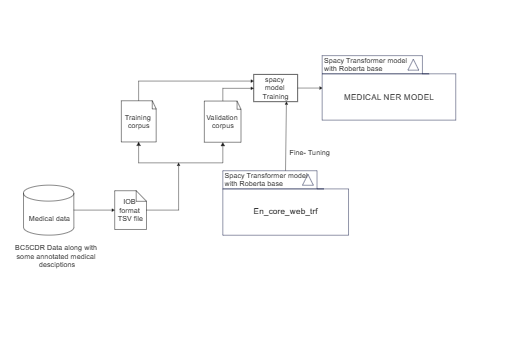
This template presents the training workflow for a medical Named Entity Recognition (NER) model. Initially, medical data is extracted and formatted into an IOB formatted TSV file, originating from the BC5CDR data, which includes certain annotated medical descriptions. Training and validation corpora are then created to facilitate the training of a Spacy model. After training, the model is fine-tuned with a Spacy Transformer model based on Roberta. The ultimate aim is to develop an accurate medical NER model. This process is vital for data scientists, NLP engineers, and informatics researchers in the medical field, assisting them in creating machine learning models capable of identifying medical terms within text.



 Desktop
Desktop